一直在听大家说用ai自动写代码,也简单尝试使用vscode+阿里通义灵码自动生成代码,但效果一直不理想;最近又出了一个Trae.ai的IDE,自带Claude-3.5-Sonnet和GPT-4o,于是去下载来体验了一下,但由于字节跳动不允许国内用户使用,只能翻墙注册登录,不过还好,ide是支持中文的。
以下是我要求ai给写的一个使用python解析pascal语法,实现99乘法表的例子,代码如下,效果图附最后:
from enum import Enum, auto
import re
# 在 TokenType 中添加 WRITE
class TokenType(Enum):
INTEGER = auto()
STRING = auto() # 新增
PLUS = auto()
MINUS = auto()
MULTIPLY = auto()
DIVIDE = auto()
LPAREN = auto()
RPAREN = auto()
EOF = auto()
BEGIN = auto()
END = auto()
SEMICOLON = auto()
DOT = auto()
ID = auto()
ASSIGN = auto()
FOR = auto()
TO = auto()
DO = auto()
WRITELN = auto()
WRITE = auto()
# 在 Lexer 的 _id 方法中添加 WRITE 识别
# 在 TokenType 枚举后添加
class Token:
def __init__(self, type, value):
self.type = type
self.value = value
def __str__(self):
return f'Token({self.type}, {self.value})'
class Lexer:
def __init__(self, text):
self.text = text
self.pos = 0
self.current_char = self.text[self.pos] if text else None
def error(self):
raise Exception('Invalid character')
def advance(self):
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char and self.current_char.isspace():
self.advance()
def integer(self):
result = ''
while self.current_char and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def string(self):
result = ''
self.advance() # 跳过开始的引号
while self.current_char and self.current_char != "'":
result += self.current_char
self.advance()
self.advance() # 跳过结束的引号
return result
def _id(self):
result = ''
while self.current_char and (self.current_char.isalnum() or self.current_char == '_'):
result += self.current_char
self.advance()
result = result.upper()
if result == 'BEGIN':
return Token(TokenType.BEGIN, 'BEGIN')
elif result == 'END':
return Token(TokenType.END, 'END')
elif result == 'FOR':
return Token(TokenType.FOR, 'FOR')
elif result == 'TO':
return Token(TokenType.TO, 'TO')
elif result == 'DO':
return Token(TokenType.DO, 'DO')
elif result == 'WRITELN':
return Token(TokenType.WRITELN, 'WRITELN')
elif result == 'WRITE':
return Token(TokenType.WRITE, 'WRITE')
else:
return Token(TokenType.ID, result)
def get_next_token(self):
while self.current_char:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char == "'":
return Token(TokenType.STRING, self.string())
if self.current_char.isalpha():
return self._id()
if self.current_char.isdigit():
return Token(TokenType.INTEGER, self.integer())
if self.current_char == ':' and self.peek() == '=':
self.advance()
self.advance()
return Token(TokenType.ASSIGN, ':=')
if self.current_char == ';':
self.advance()
return Token(TokenType.SEMICOLON, ';')
if self.current_char == '.':
self.advance()
return Token(TokenType.DOT, '.')
if self.current_char == '+':
self.advance()
return Token(TokenType.PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(TokenType.MINUS, '-')
if self.current_char == '*':
self.advance()
return Token(TokenType.MULTIPLY, '*')
if self.current_char == '/':
self.advance()
return Token(TokenType.DIVIDE, '/')
if self.current_char == '(':
self.advance()
return Token(TokenType.LPAREN, '(')
if self.current_char == ')':
self.advance()
return Token(TokenType.RPAREN, ')')
if self.current_char == '>':
self.advance()
return Token(TokenType.GREATER, '>')
if self.current_char == '<':
self.advance()
return Token(TokenType.LESS, '<')
if self.current_char == '=':
self.advance()
return Token(TokenType.EQUAL, '=')
self.error()
return Token(TokenType.EOF, None)
def peek(self):
peek_pos = self.pos + 1
if peek_pos > len(self.text) - 1:
return None
return self.text[peek_pos]
# TokenType 枚举定义后,添加所有 AST 相关的类定义
class AST:
pass
class String(AST):
def __init__(self, token):
self.token = token
self.value = token.value
class BinOp(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = right
class Num(AST):
def __init__(self, token):
self.token = token
self.value = token.value
class Var(AST):
def __init__(self, token):
self.token = token
self.value = token.value
class Assign(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = right
class For(AST):
def __init__(self, var, start, end, statements):
self.var = var
self.start = start
self.end = end
self.statements = statements
class Writeln(AST):
def __init__(self, expr):
self.expr = expr
class Write(AST):
def __init__(self, expr):
self.expr = expr
# 在 Interpreter 类中添加 write 支持
# 在 AST 类定义后添加完整的 Interpreter 类
class Interpreter:
def __init__(self, lexer):
self.lexer = lexer
self.current_token = self.lexer.get_next_token()
self.variables = {}
# 删除这里的 String 类定义
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
# 添加 String AST 节点
# String AST 节点应该在 AST 相关类定义部分
# 在 AST 相关类定义部分添加
class String(AST):
def __init__(self, token):
self.token = token
self.value = token.value
def term(self):
node = self.factor()
while self.current_token.type in (TokenType.MULTIPLY, TokenType.DIVIDE):
token = self.current_token
if token.type == TokenType.MULTIPLY:
self.eat(TokenType.MULTIPLY)
elif token.type == TokenType.DIVIDE:
self.eat(TokenType.DIVIDE)
node = BinOp(left=node, op=token, right=self.factor())
return node
def expr(self):
node = self.term()
while self.current_token.type in (TokenType.PLUS, TokenType.MINUS):
token = self.current_token
if token.type == TokenType.PLUS:
self.eat(TokenType.PLUS)
elif token.type == TokenType.MINUS:
self.eat(TokenType.MINUS)
node = BinOp(left=node, op=token, right=self.term())
return node
def statement(self):
if self.current_token.type == TokenType.ID:
node = self.assignment_statement()
self.eat(TokenType.SEMICOLON)
return node
elif self.current_token.type == TokenType.FOR:
node = self.for_statement()
self.eat(TokenType.SEMICOLON)
return node
elif self.current_token.type == TokenType.WRITELN:
node = self.writeln_statement()
self.eat(TokenType.SEMICOLON)
return node
elif self.current_token.type == TokenType.WRITE:
node = self.write_statement()
self.eat(TokenType.SEMICOLON)
return node
def statements(self):
self.eat(TokenType.BEGIN)
statements = []
while self.current_token.type != TokenType.END:
statements.append(self.statement())
self.eat(TokenType.END)
self.eat(TokenType.DOT)
return statements
def visit(self, node):
if isinstance(node, String):
return node.value
if isinstance(node, Write):
value = self.visit(node.expr)
print(value, end='')
return None
if isinstance(node, Writeln):
value = self.visit(node.expr)
print(value)
return None
if isinstance(node, For):
var_name = node.var.value
start_val = self.visit(node.start)
end_val = self.visit(node.end)
for i in range(start_val, end_val + 1):
self.variables[var_name] = i
for stmt in node.statements:
self.visit(stmt)
return None
if isinstance(node, BinOp):
if node.op.type == TokenType.PLUS:
return self.visit(node.left) + self.visit(node.right)
elif node.op.type == TokenType.MINUS:
return self.visit(node.left) - self.visit(node.right)
elif node.op.type == TokenType.MULTIPLY:
return self.visit(node.left) * self.visit(node.right)
elif node.op.type == TokenType.DIVIDE:
return self.visit(node.left) / self.visit(node.right)
elif isinstance(node, Num):
return node.value
elif isinstance(node, Var):
return self.variables.get(node.value, 0)
elif isinstance(node, Assign):
var_name = node.left.value
self.variables[var_name] = self.visit(node.right)
return self.variables[var_name]
def interpret(self):
statements = self.statements()
for statement in statements:
self.visit(statement)
return self.variables
def assignment_statement(self):
var = Var(self.current_token)
self.eat(TokenType.ID)
token = self.current_token
self.eat(TokenType.ASSIGN)
return Assign(var, token, self.expr())
def for_statement(self):
self.eat(TokenType.FOR)
var = Var(self.current_token)
self.eat(TokenType.ID)
self.eat(TokenType.ASSIGN)
start = self.expr()
self.eat(TokenType.TO)
end = self.expr()
self.eat(TokenType.DO)
statements = []
if self.current_token.type == TokenType.BEGIN:
self.eat(TokenType.BEGIN)
while self.current_token.type != TokenType.END:
statements.append(self.statement())
self.eat(TokenType.END)
else:
statements.append(self.statement())
return For(var, start, end, statements)
def writeln_statement(self):
self.eat(TokenType.WRITELN)
self.eat(TokenType.LPAREN)
expr = self.expr()
self.eat(TokenType.RPAREN)
return Writeln(expr)
def write_statement(self):
self.eat(TokenType.WRITE)
self.eat(TokenType.LPAREN)
expr = self.expr()
self.eat(TokenType.RPAREN)
return Write(expr)
def factor(self):
token = self.current_token
if token.type == TokenType.INTEGER:
self.eat(TokenType.INTEGER)
return Num(token)
elif token.type == TokenType.STRING:
self.eat(TokenType.STRING)
return String(token)
elif token.type == TokenType.ID:
self.eat(TokenType.ID)
return Var(token)
elif token.type == TokenType.LPAREN:
self.eat(TokenType.LPAREN)
node = self.expr()
self.eat(TokenType.RPAREN)
return node
def main():
text = """
BEGIN
FOR i := 1 TO 9 DO
BEGIN
FOR j := 1 TO i DO
BEGIN
write(j);
write('*');
write(i);
write('=');
write(i * j);
write(' ');
END;
writeln('');
END;
for n:=1 to 100 do
begin
m:=m+n;
end;
writeln(m);
END.
"""
try:
lexer = Lexer(text)
interpreter = Interpreter(lexer)
result = interpreter.interpret()
print("最终变量值:", result)
except Exception as e:
print("错误:", str(e))
if __name__ == '__main__':
main()
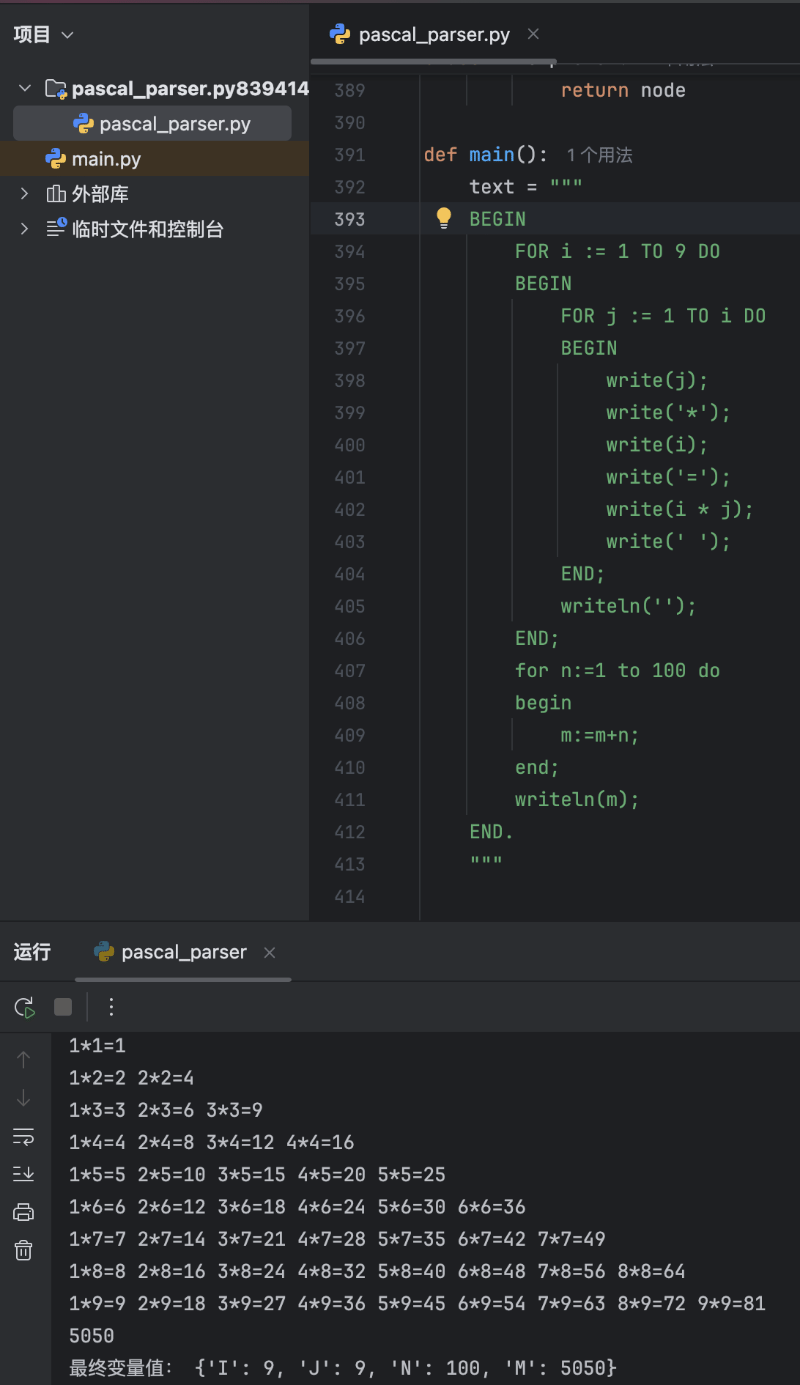
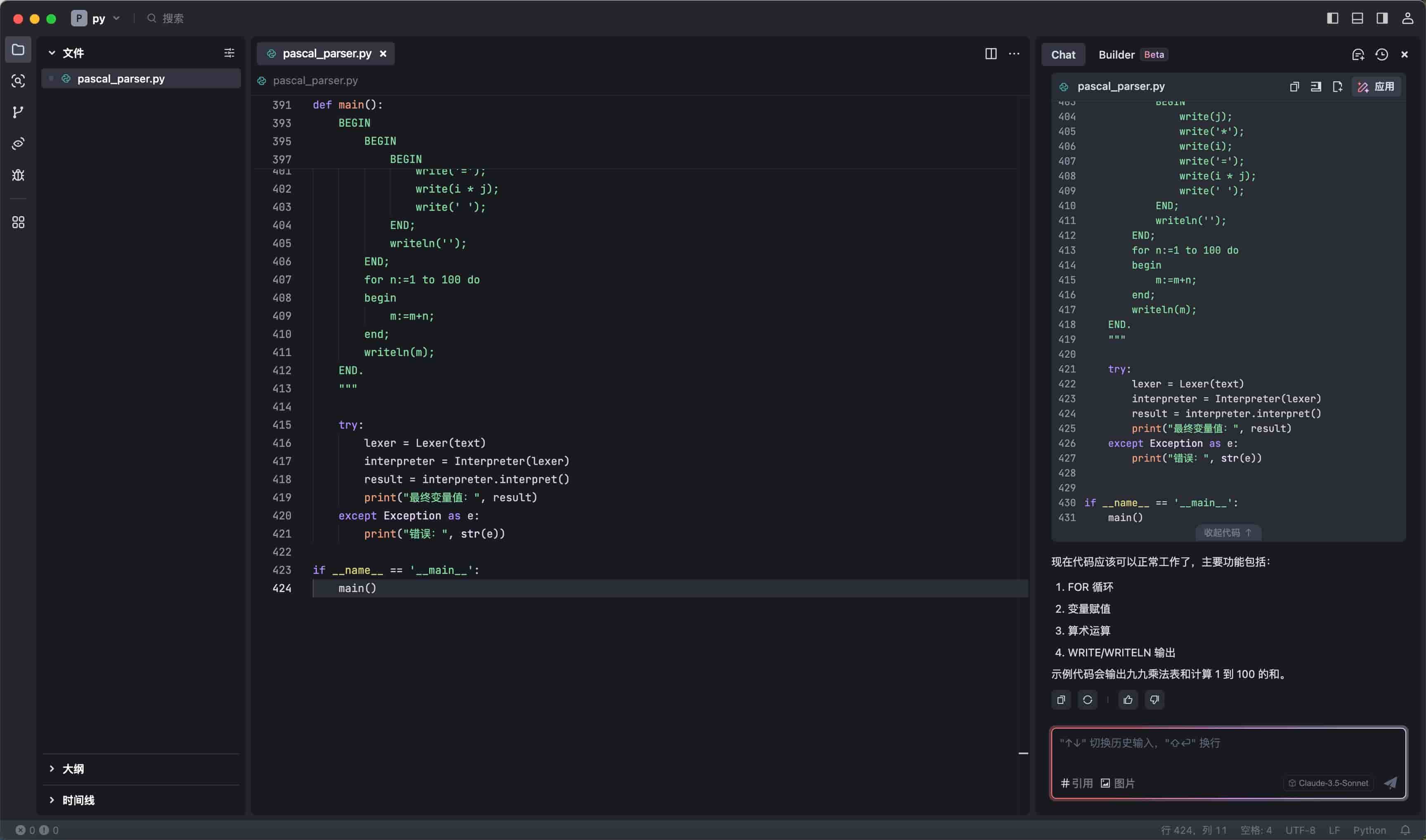
代码全部由ai自动生成,但我花了大量的时间让ai重复修正错误,所以,目前的ai虽然能自动按要求生成代码,但还是需要懂代码的人去校验和辅助实现。